如何让大模型看懂文档
RAG 实践中的文档解析
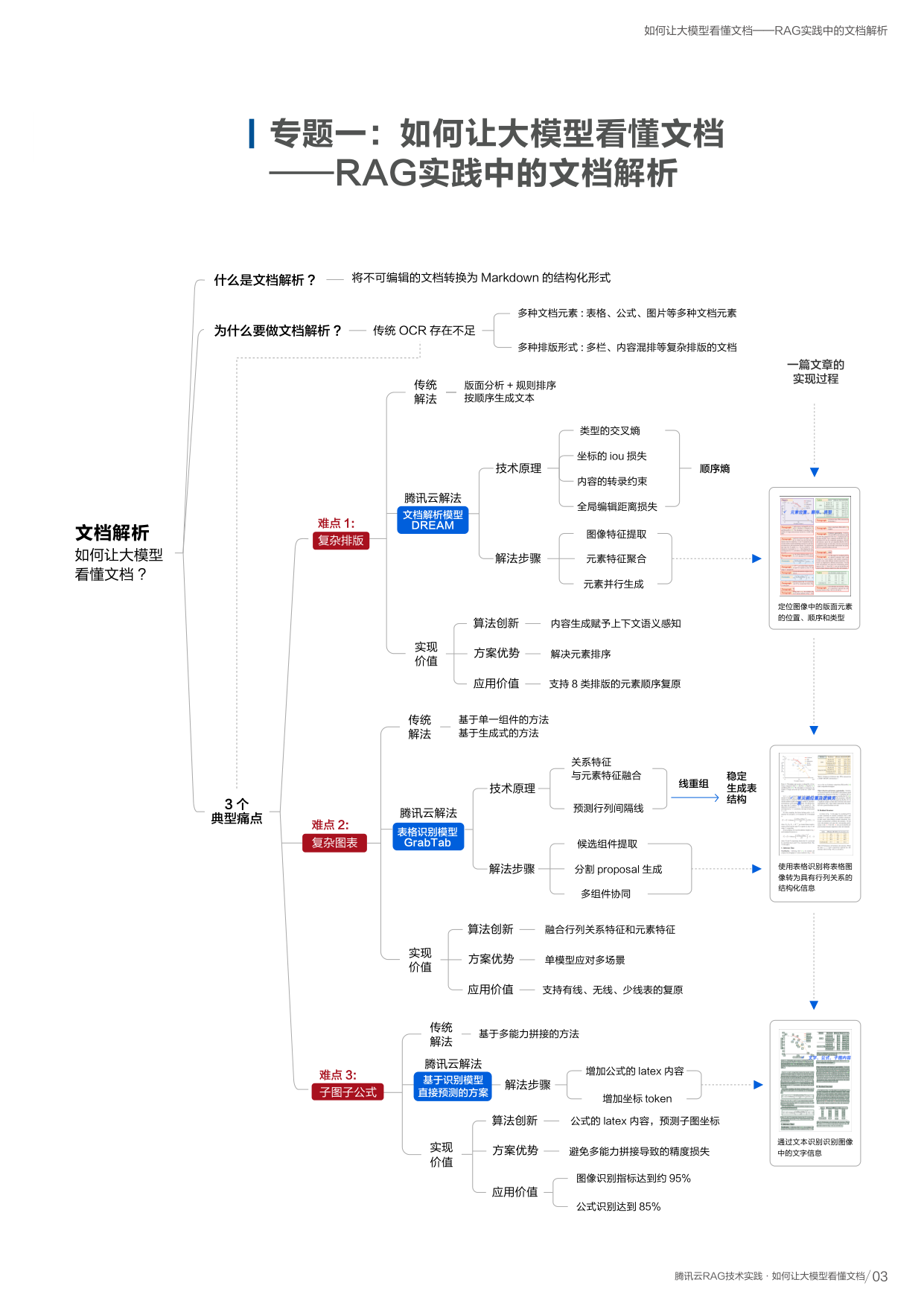
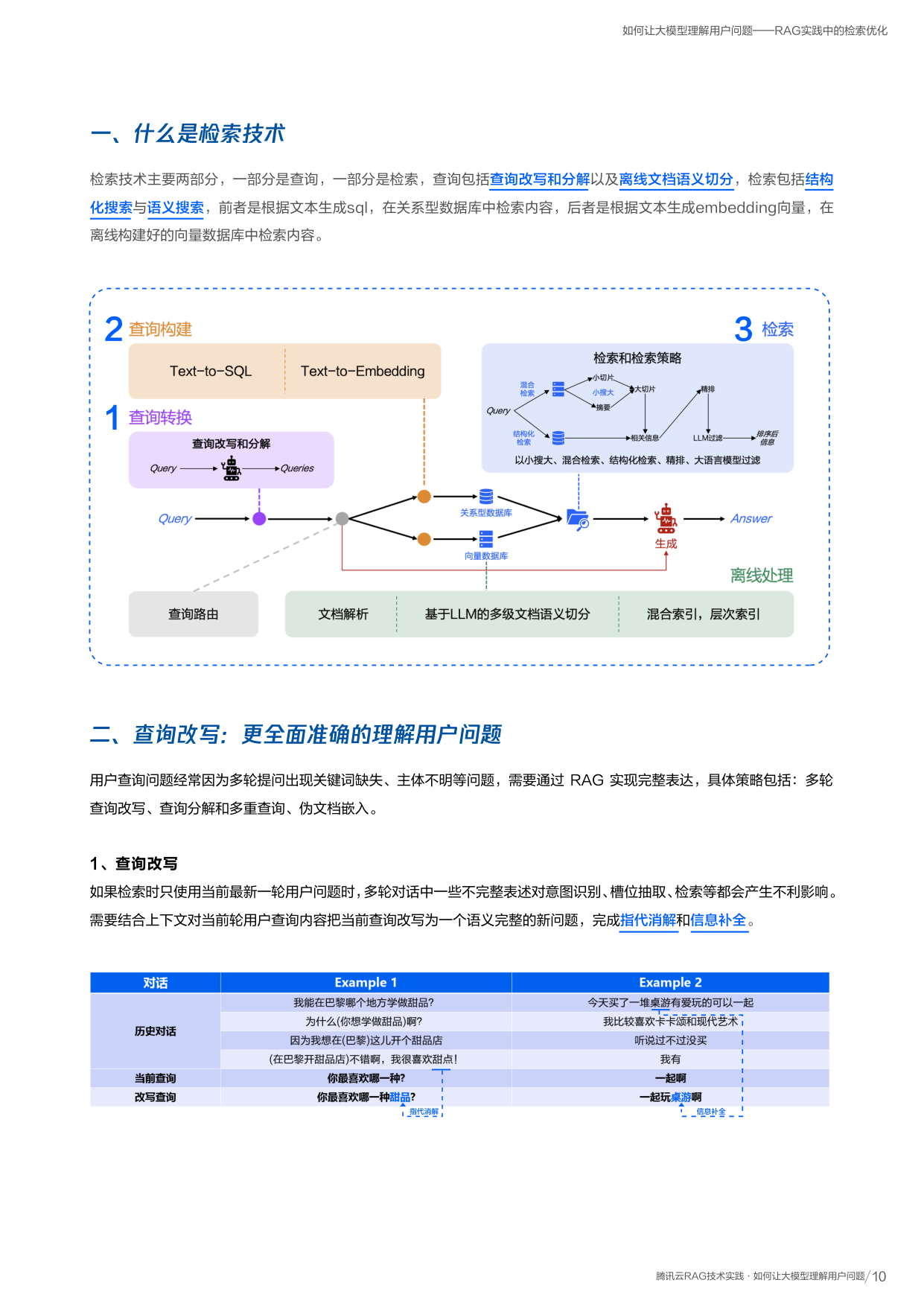
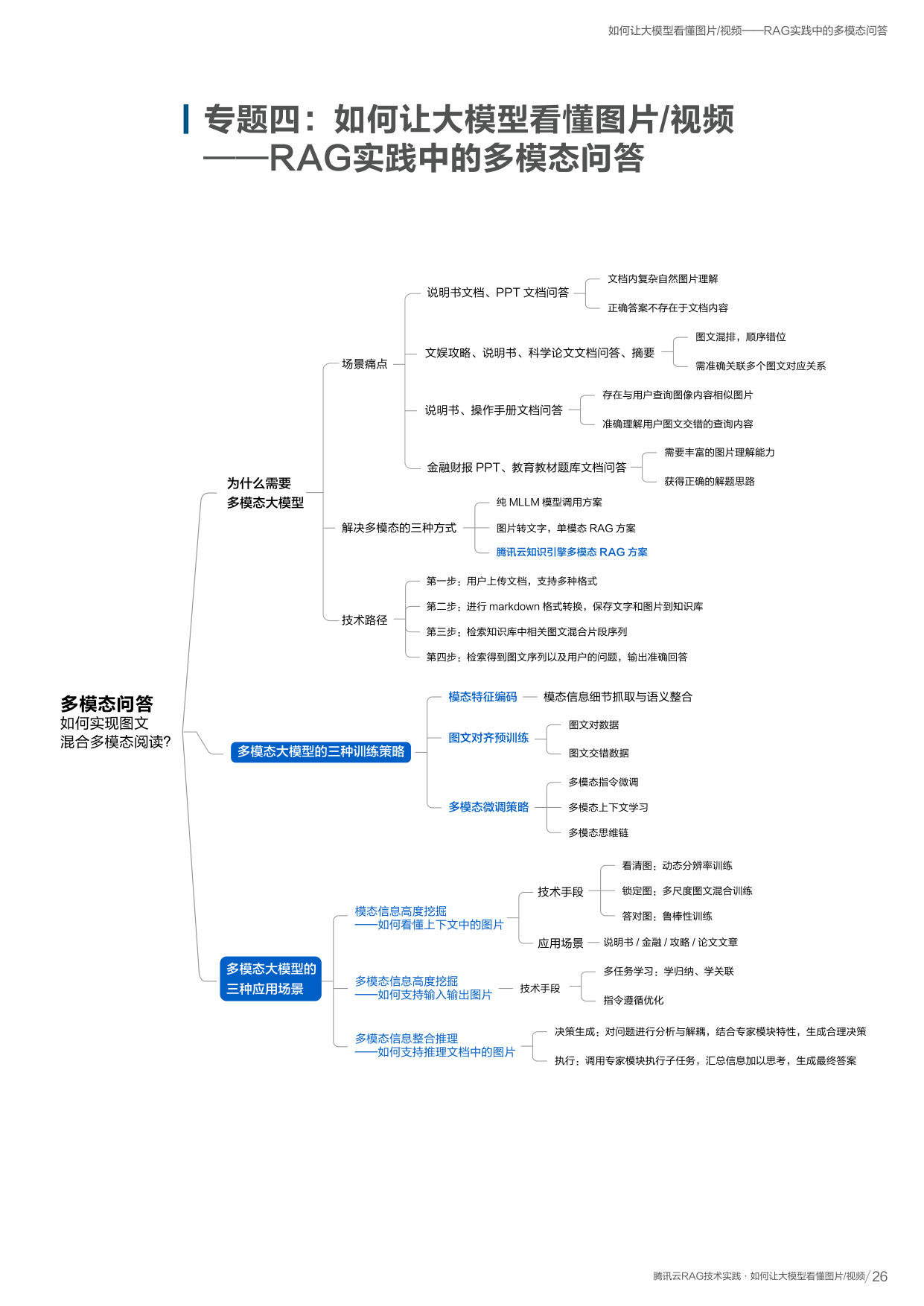
什么是文档解析?为什么要做?
将 PDF、Word、图片等不可编辑的文档,转换为 Markdown 结构化形式,识别其中的段落、表格、公式、标题、图片等元素的内容及阅读顺序。 课程笔记: Pipeline B
普遍文档以 PDF 和图片形式存在,无法直接被大模型使用。传统 OCR 只能识别纯文字,远远不够:
传统 OCR 的局限
- 只能识别文字,忽略表格、公式、图片
- 无法处理多栏、图文混排等复杂排版
- 输出的文字顺序经常混乱
文档解析的能力
- 识别多种元素(表格、公式、子图、标题等)
- 正确排列阅读顺序(跨栏、环绕等复杂版式)
- 输出结构化 Markdown,大模型可直接使用
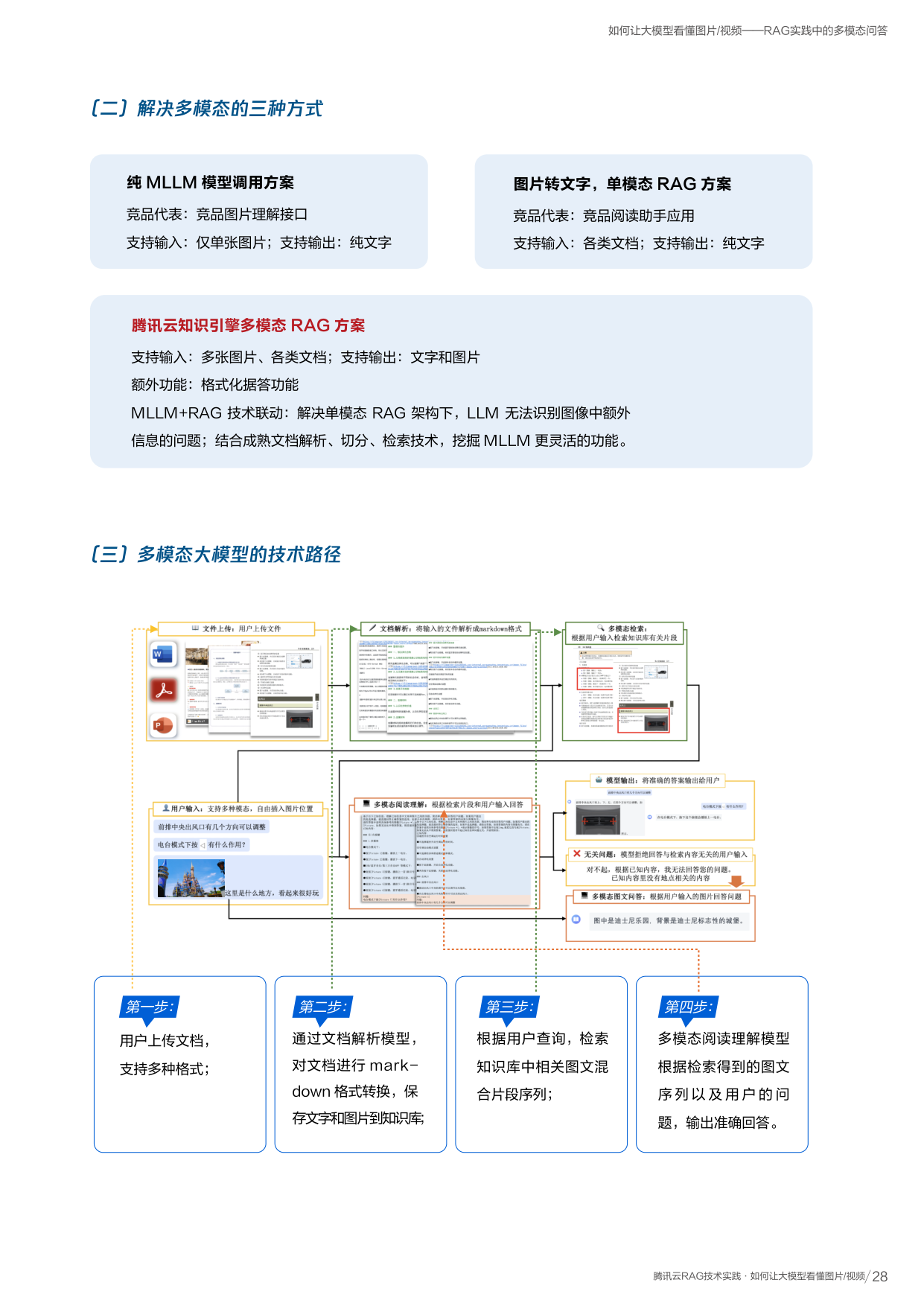
文档解析的四步实现过程
版面分析
定位图像中版面元素(段落、表格、图片、标题等)的位置、顺序和类型
文字识别
识别图像中的文字信息
表格识别
将表格图像转为具有行列关系的结构化信息
内容整合
将所有识别结果按阅读顺序整合为 Markdown 内容
难点一:复杂排版的阅读顺序问题 笔记: Pipeline C
文档解析结果要作为大模型输入,所以阅读顺序必须正确。但真实文档中存在图/表群组、跨栏段落、图表文环绕等复杂排版,传统解法搞不定。
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 版面分析 + 规则排序 | 检测版面元素后按规则排列 | 实现快捷,满足简单排版 | 无法处理图文表混排等复杂场景 |
| 自回归生成文本 | 输入无序内容,自回归生成有序文本 | 纯文字排序效果可以 | 无法处理非文字元素,细粒度性能差 |
| DREAM 模型(腾讯云) 笔记 | 自回归并行解码 + 语义感知 | 解决各种复杂排版 | — |
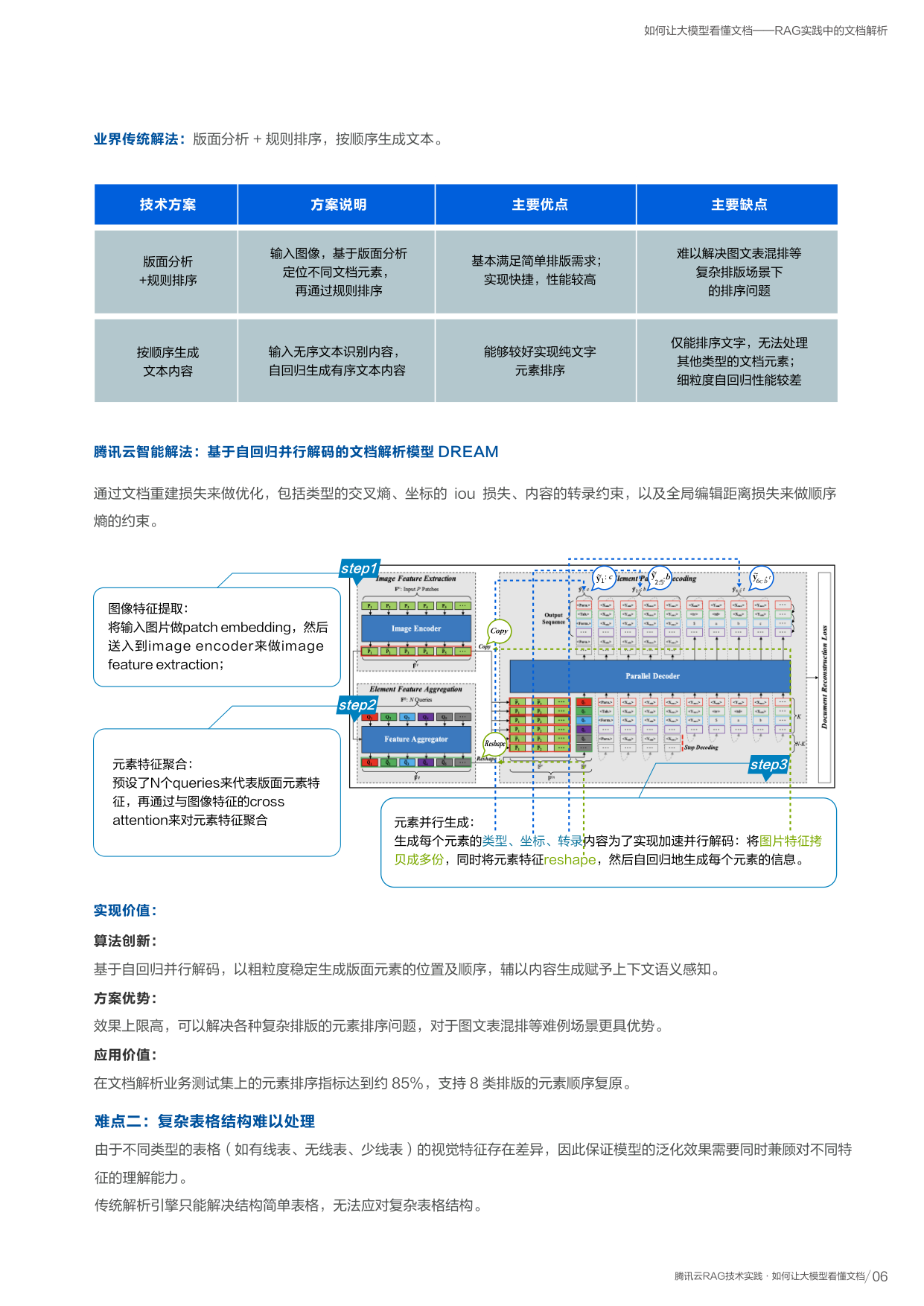
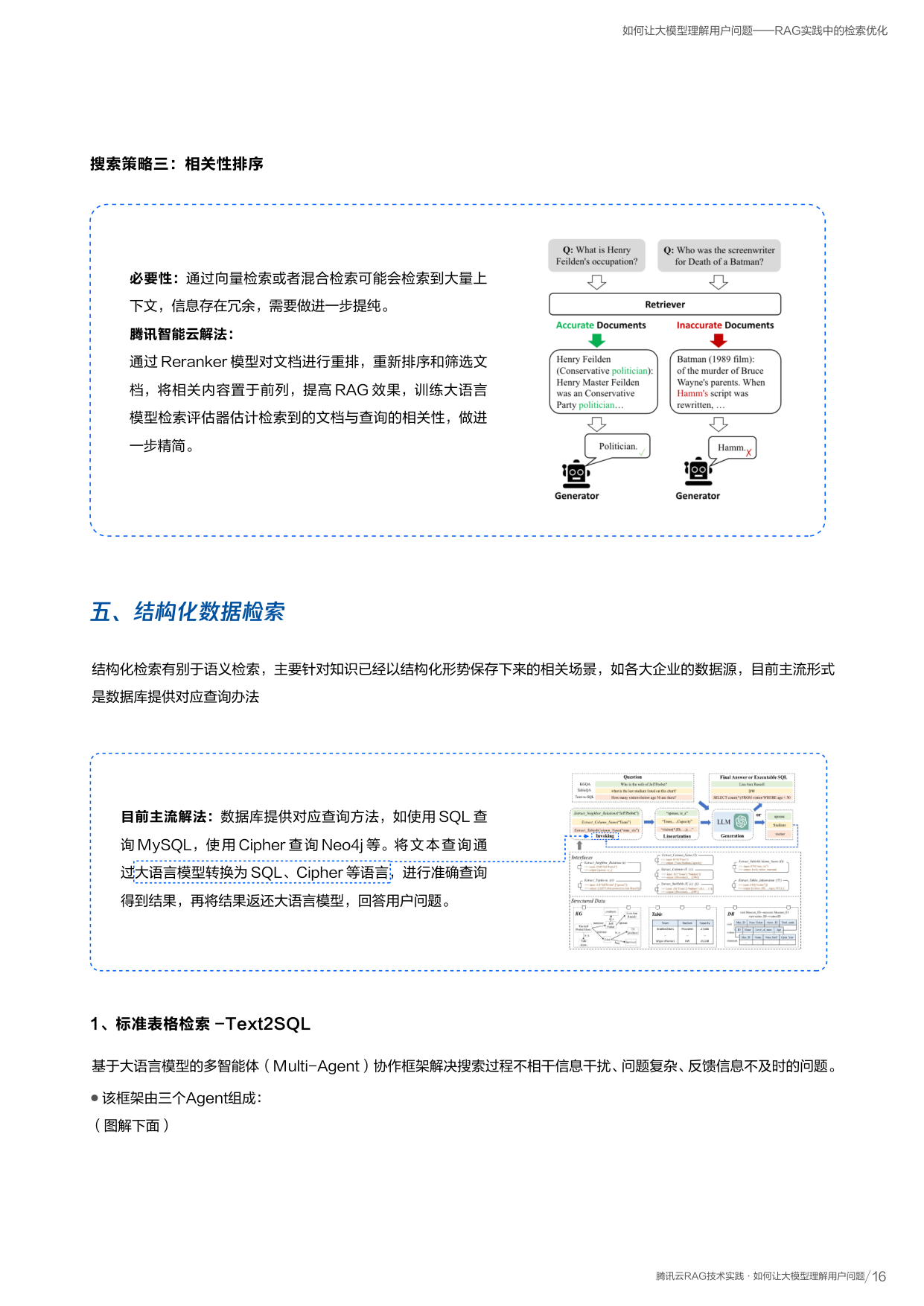
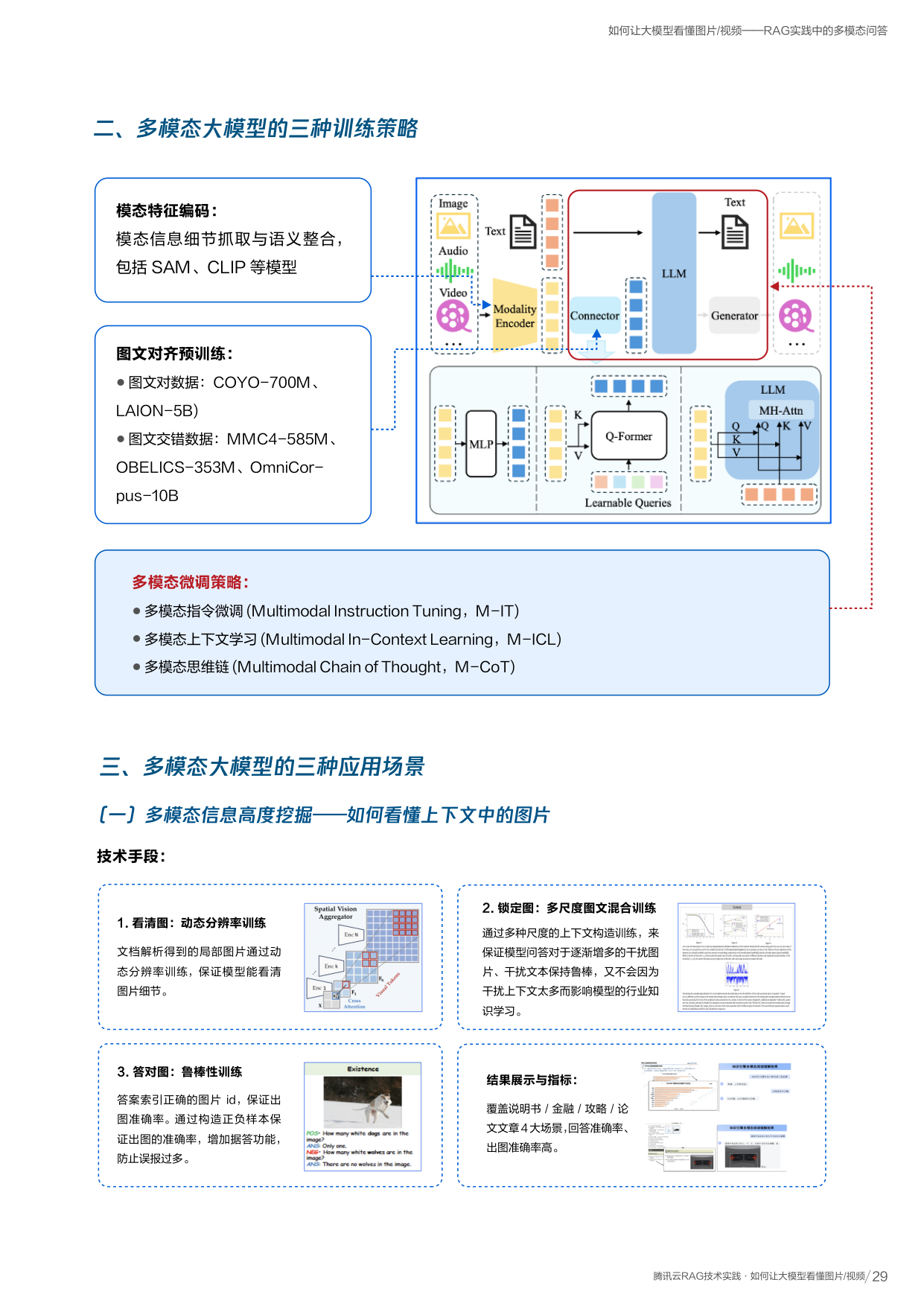
深入了解:DREAM 模型工作原理
把文档图片交给模型,模型像人一样先"看全局",再"找到每个元素",最后"按正确顺序读出来"。
图像特征提取
将输入图片切成小块(patch),送入图像编码器提取视觉特征
元素特征聚合
预设 N 个查询向量代表版面元素,通过注意力机制与图像特征交互,聚合每个元素的信息
元素并行生成
同时生成每个元素的类型、坐标和内容。将图片特征拷贝多份实现并行解码加速
难点二:复杂表格结构难以处理
不同类型表格(有线表、无线表、少线表)视觉差异大。有些用实线分隔,有些用空白分隔,模型需要同时应对所有情况。
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 基于单一组件 | 边界提取或元素关系预测 | 各独立场景精度基本满足 | 存在效果瓶颈,优化成本高 |
| 基于生成式方法 | 自回归模型端到端生成结构 | 可积累训练数据 | 预测不稳定,复杂表格准确率低 |
| GrabTab 模型(腾讯云) | 特征协同 + 线重组 | 单模型应对多场景 | — |
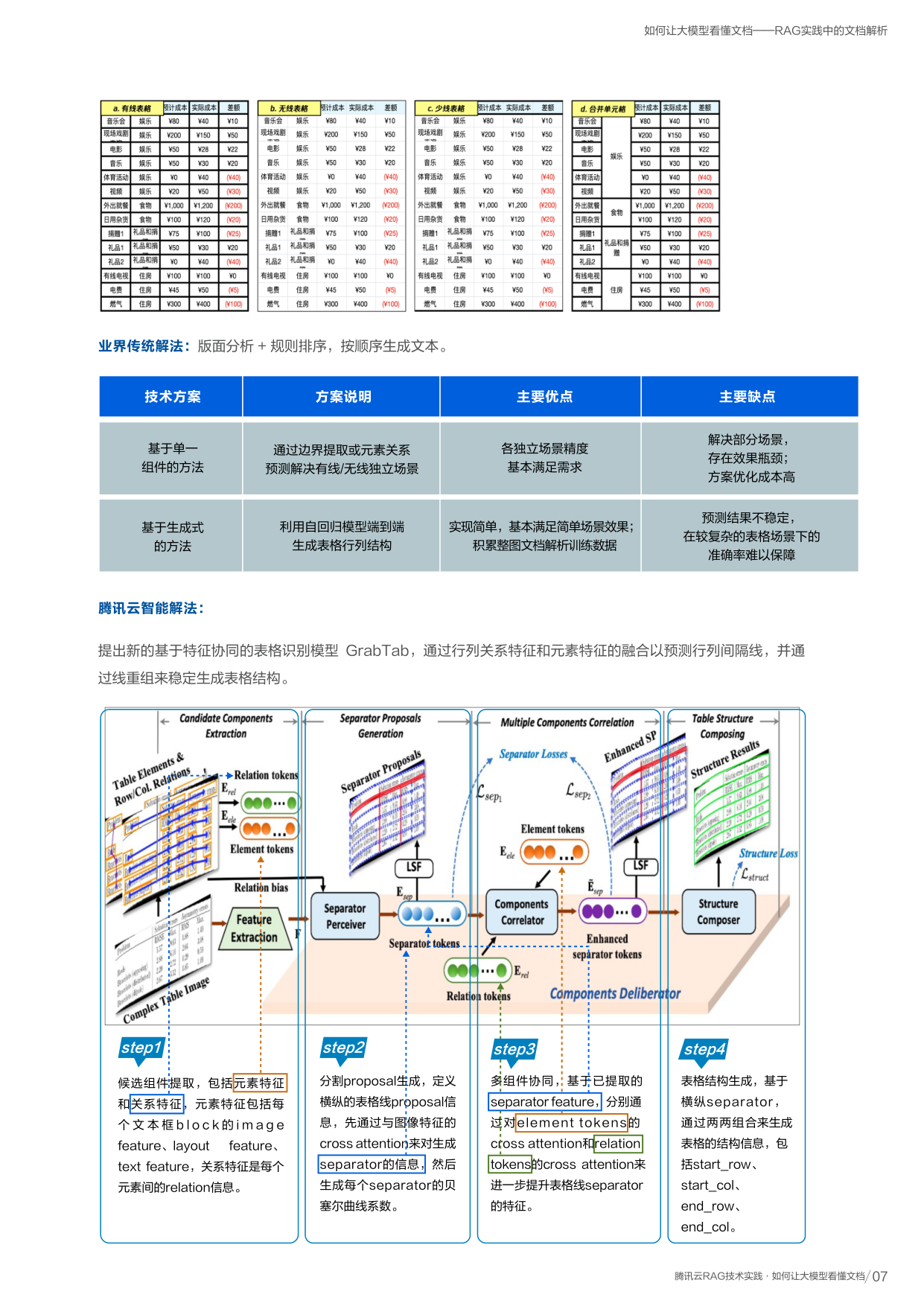
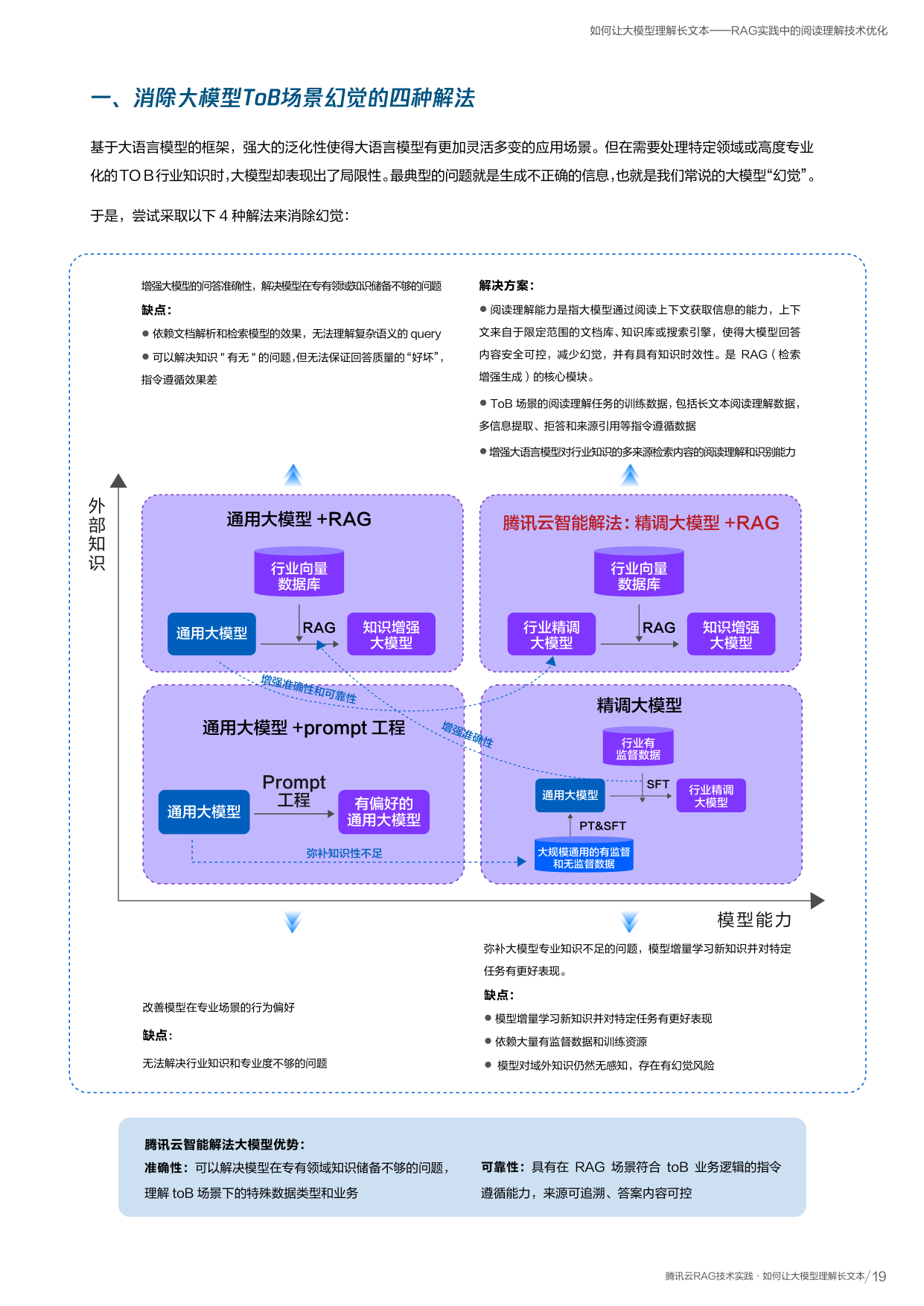
深入了解:GrabTab 模型工作原理
先找到表格里每个文字块的特征,再找出文字块之间的关系,然后预测分隔线在哪里,最后用这些线组装出完整的表格。
候选组件提取
提取元素特征(每个文本块的图像/布局/文字特征)和关系特征(元素间的关联信息)
分割线生成
定义横纵表格线,通过注意力机制生成每条分隔线的贝塞尔曲线系数
多组件协同
基于已提取的分隔线特征,与元素和关系做交叉注意力进一步提升精度
表格结构生成
基于横纵分隔线两两组合,生成每个单元格的行列坐标信息
难点三:子图子公式识别
真实文档中,公式和子图经常嵌在文字行内。传统做法是先定位再分别识别再拼接——每步都会累积误差。
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 多能力拼接 | 先定位子元素,再调用各模型拼接 | 各能力解耦,独立优化 | 传递误差大,规则需频繁适配 |
| 识别模型直接预测(腾讯云) | 一个模型同时输出文字+公式+子图 | 避免拼接误差,上限高,实现简单 | — |
在常规文字识别基础上,增加对文本行内公式的 LaTeX 内容输出,并预测行内子图的坐标位置。一个模型端到端完成,无需多模型接力。